Kalman et al.
Note
The support for the directives below starts with commit
1146c83d9f9832630e97daab3ec7359705dc2c77 in the development branch
Release 1.9.30.x will be the 1st to include it.
One of the original goals of backtrader was to be pure python, i.e.: to only
use packages available in the standard distribution. A single exception was
made with matplotlib to have plotting without reinventing the
wheel. Although is imported at the latest possible moment to avoid disrupting
standard operations which may not require plotting at all (and avoiding errors
if not installed and not wished)
A 2nd exception was partially made with pytz when adding support for
timezones with the advent of live data feeds which may reside outside of the
local timezone. Again the import action happens in the background and only if
pytz is available (the user may choose to pass pytz instances)
But the moment has come to make a full exception, because backtraders are
using well known packages like numpy, pandas, statsmodel and some
more modest ones like pykalman. Or else inclusion in the platform of things
which use those packages.
Some examples from the community:
This wish was added to the quick roadmap sketched here:
The declarative approach
Key in keeping the original spirit of backtrader and at the same allowing the use of those packages is to not force pure python users to have to install those packages.
Although this may seem challenging and prone to multiple conditional statements here and there, together with exception handling, the approach both internally in the platform and externally for users is to rely on the same principles already used to develop other concepts, like for example parameters (named params) for most objects.
Let’s recall how one defines an Indicator accepting params and defining
lines:
class MyIndicator(bt.Indicator):
lines = ('myline',)
params = (
('period', 50),
)
With the parameter period later being addressable as
self.params.period or self.p.period as in:
def __init__(self):
print('my period is:', self.p.period)
and the current value in the line as self.lines.myline or self.l.myline
as in:
def next(self):
print('mylines[0]:', self.lines.myline[0])
This not being particularly useful, just showing the declarative approach of the params background machinery which also features proper support for inheritance (including multiple inheritance)
Introducing packages
Using the same declarative technique (some would call it metaprogramming) the support for foreign packages is available as:
class MyIndicator(bt.Indicator):
packages = ('pandas',)
lines = ('myline',)
params = (
('period', 50),
)
Blistering barnacles!!! It seems just another declaration. The first question for the implementer of the indicator would be:
- Do I have to manually import ``pandas``?
And the answer is a straightforward: No. The background machinery will
import pandas and make it available in the module in which MyIndicator
is defined. One could now do the following in next:
def next(self):
print('mylines[0]:', pandas.SomeFunction(self.lines.myline[0]))
The packages directive can be used also to:
-
Import multiple packages in one single declaration
-
Assign the import to an alias ala
import pandas as pd
Let’s say that statsmodel is also wished as sm to complete
pandas.SomeFunction:
class MyIndicator(bt.Indicator):
packages = ('pandas', ('statsmodel', 'sm'),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', sm.XX(pandas.SomeFunction(self.lines.myline[0])))
statsmodel has been imported as sm and is available. It simply takes
passing an iterable (a tuple is the backtrader convention) with the name
of the package and the wished alias.
Adding frompackages
Python is well known for the constant lookup for things which is one of the reasons for the language to be fantastic with regards to dynamism, introspection facilities and metaprogramming. At the same time is also one of the causes for not being able to deliver the same performance.
One of the usual speed ups is to remove lookup into modules by directly
importing symbols from the modules, to have local lookups. With our
SomeFunction from pandas this would look like:
from pandas import SomeFunction
or with an alias:
from pandas import SomeFunction as SomeFunc
backtrader offers support for both with the frompackages
directive. Let’s rework MyIndicator:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', 'SomeFunction'),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction(self.lines.myline[0]))
Of course, this starts adding more parenthesis. For example if two (2) things
are going to be imported from pandas, it would seem like this:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', ['SomeFunction', 'SomeFunction2']),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction2(SomeFunction(self.lines.myline[0])))
Where for the sake of clarity SomeFunction and SomeFunction2 have been
put in in a list instead of a tuple, to have square brackets, []
and be able to read it it a bit better.
One can also alias SomeFunction to for example SFunc. The full example:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', [('SomeFunction', 'SFunc'), 'SomeFunction2']),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction2(SFunc(self.lines.myline[0])))
And importing from different packages is possible at the expense of more parenthesis. Of course line breaks and indentation do help:
class MyIndicator(bt.Indicator):
frompackages = (
('pandas', [('SomeFunction', 'SFunc'), 'SomeFunction2']),
('statsmodel', 'XX'),
)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', XX(SomeFunction2(SFunc(self.lines.myline[0]))))
Using inheritance
Both packages and frompackages support (multiple) inheritance. There
could for example be a base class which adds numpy support to all
subclasses:
class NumPySupport(object):
packages = ('numpy',)
class MyIndicator(bt.Indicator, NumPySupport):
packages = ('pandas',)
MyIndicator will require from the background machinery the import of both
numpy and pandas and will be able to use them.
Introducing Kalman and friends
Note
both indicators below would need peer reviewing to confirm the implementations. Use with care.
A sample implementing a KalmanMovingAverage can be found below. This is
modeled after a post here: Quantopian Lecture Series: Kalman Filters
The implementation:
class KalmanMovingAverage(bt.indicators.MovingAverageBase):
packages = ('pykalman',)
frompackages = (('pykalman', [('KalmanFilter', 'KF')]),)
lines = ('kma',)
alias = ('KMA',)
params = (
('initial_state_covariance', 1.0),
('observation_covariance', 1.0),
('transition_covariance', 0.05),
)
plotlines = dict(cov=dict(_plotskip=True))
def __init__(self):
self.addminperiod(self.p.period) # when to deliver values
self._dlast = self.data(-1) # get previous day value
def nextstart(self):
self._k1 = self._dlast[0]
self._c1 = self.p.initial_state_covariance
self._kf = pykalman.KalmanFilter(
transition_matrices=[1],
observation_matrices=[1],
observation_covariance=self.p.observation_covariance,
transition_covariance=self.p.transition_covariance,
initial_state_mean=self._k1,
initial_state_covariance=self._c1,
)
self.next()
def next(self):
k1, self._c1 = self._kf.filter_update(self._k1, self._c1, self.data[0])
self.lines.kma[0] = self._k1 = k1
And a KalmanFilter following a post here: Kalman Filter-Based Pairs
Trading Strategy In QSTrader
class NumPy(object):
packages = (('numpy', 'np'),)
class KalmanFilterInd(bt.Indicator, NumPy):
_mindatas = 2 # needs at least 2 data feeds
packages = ('pandas',)
lines = ('et', 'sqrt_qt')
params = dict(
delta=1e-4,
vt=1e-3,
)
def __init__(self):
self.wt = self.p.delta / (1 - self.p.delta) * np.eye(2)
self.theta = np.zeros(2)
self.P = np.zeros((2, 2))
self.R = None
self.d1_prev = self.data1(-1) # data1 yesterday's price
def next(self):
F = np.asarray([self.data0[0], 1.0]).reshape((1, 2))
y = self.d1_prev[0]
if self.R is not None: # self.R starts as None, self.C set below
self.R = self.C + self.wt
else:
self.R = np.zeros((2, 2))
yhat = F.dot(self.theta)
et = y - yhat
# Q_t is the variance of the prediction of observations and hence
# \sqrt{Q_t} is the standard deviation of the predictions
Qt = F.dot(self.R).dot(F.T) + self.p.vt
sqrt_Qt = np.sqrt(Qt)
# The posterior value of the states \theta_t is distributed as a
# multivariate Gaussian with mean m_t and variance-covariance C_t
At = self.R.dot(F.T) / Qt
self.theta = self.theta + At.flatten() * et
self.C = self.R - At * F.dot(self.R)
# Fill the lines
self.lines.et[0] = et
self.lines.sqrt_qt[0] = sqrt_Qt
Which for the sake of it shows how packages also work with inheritance
(pandas is not really needed)
An execution of the sample:
$ ./kalman-things.py --plot
produces this chart
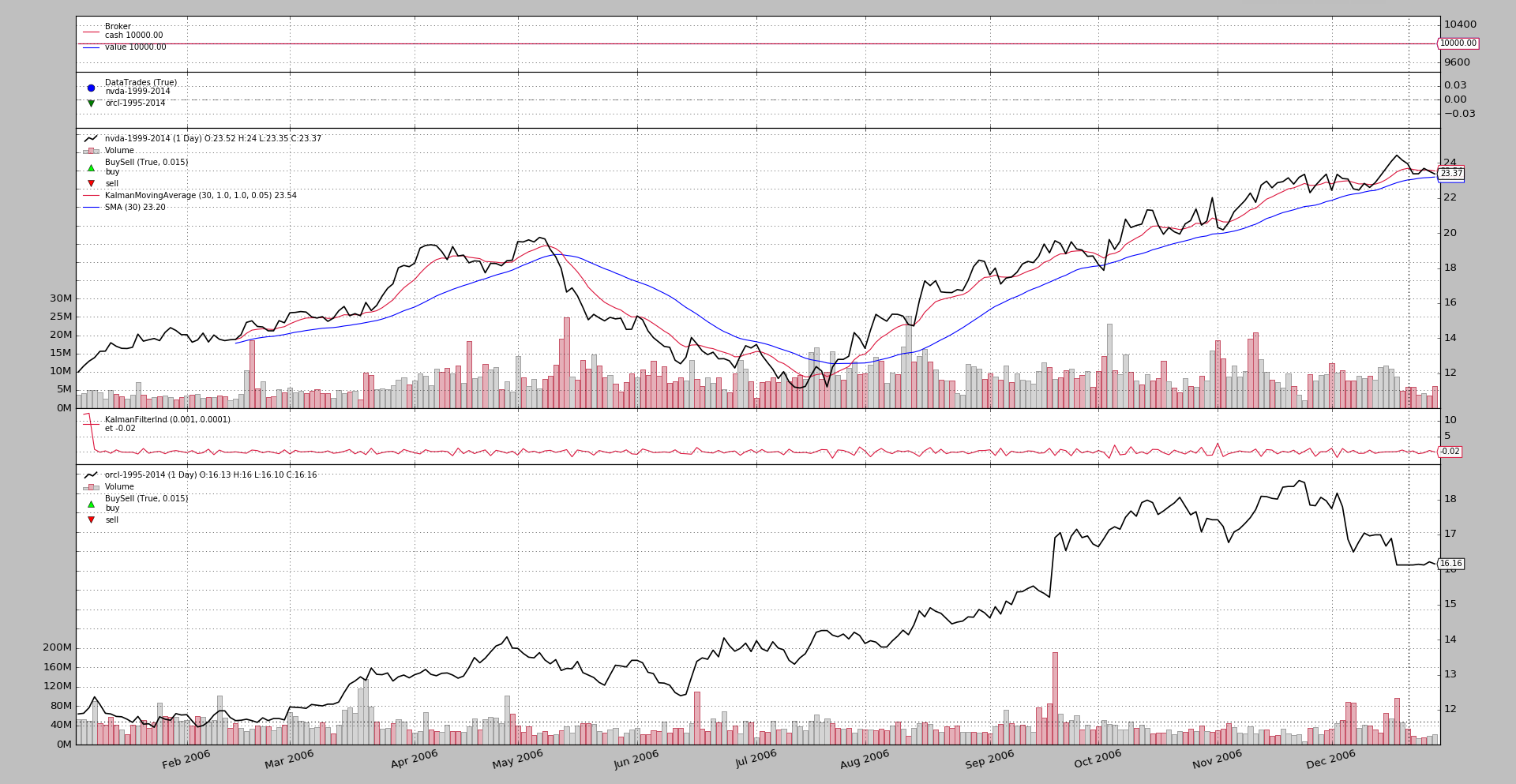
Sample Usage
$ ./kalman-things.py --help
usage: kalman-things.py [-h] [--data0 DATA0] [--data1 DATA1]
[--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]]
Packages and Kalman
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/nvda-1999-2014.txt)
--data1 DATA1 Data to read in (default:
../../datas/orcl-1995-2014.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2006-01-01)
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2007-01-01)
--cerebro kwargs kwargs in key=value format (default: runonce=False)
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
Sample Code
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class KalmanMovingAverage(bt.indicators.MovingAverageBase):
packages = ('pykalman',)
frompackages = (('pykalman', [('KalmanFilter', 'KF')]),)
lines = ('kma',)
alias = ('KMA',)
params = (
('initial_state_covariance', 1.0),
('observation_covariance', 1.0),
('transition_covariance', 0.05),
)
def __init__(self):
self.addminperiod(self.p.period) # when to deliver values
self._dlast = self.data(-1) # get previous day value
def nextstart(self):
self._k1 = self._dlast[0]
self._c1 = self.p.initial_state_covariance
self._kf = pykalman.KalmanFilter(
transition_matrices=[1],
observation_matrices=[1],
observation_covariance=self.p.observation_covariance,
transition_covariance=self.p.transition_covariance,
initial_state_mean=self._k1,
initial_state_covariance=self._c1,
)
self.next()
def next(self):
k1, self._c1 = self._kf.filter_update(self._k1, self._c1, self.data[0])
self.lines.kma[0] = self._k1 = k1
class NumPy(object):
packages = (('numpy', 'np'),)
class KalmanFilterInd(bt.Indicator, NumPy):
_mindatas = 2 # needs at least 2 data feeds
packages = ('pandas',)
lines = ('et', 'sqrt_qt')
params = dict(
delta=1e-4,
vt=1e-3,
)
def __init__(self):
self.wt = self.p.delta / (1 - self.p.delta) * np.eye(2)
self.theta = np.zeros(2)
self.R = None
self.d1_prev = self.data1(-1) # data1 yesterday's price
def next(self):
F = np.asarray([self.data0[0], 1.0]).reshape((1, 2))
y = self.d1_prev[0]
if self.R is not None: # self.R starts as None, self.C set below
self.R = self.C + self.wt
else:
self.R = np.zeros((2, 2))
yhat = F.dot(self.theta)
et = y - yhat
# Q_t is the variance of the prediction of observations and hence
# \sqrt{Q_t} is the standard deviation of the predictions
Qt = F.dot(self.R).dot(F.T) + self.p.vt
sqrt_Qt = np.sqrt(Qt)
# The posterior value of the states \theta_t is distributed as a
# multivariate Gaussian with mean m_t and variance-covariance C_t
At = self.R.dot(F.T) / Qt
self.theta = self.theta + At.flatten() * et
self.C = self.R - At * F.dot(self.R)
# Fill the lines
self.lines.et[0] = et
self.lines.sqrt_qt[0] = sqrt_Qt
class KalmanSignals(bt.Indicator):
_mindatas = 2 # needs at least 2 data feeds
lines = ('long', 'short',)
def __init__(self):
kf = KalmanFilterInd()
et, sqrt_qt = kf.lines.et, kf.lines.sqrt_qt
self.lines.long = et < -1.0 * sqrt_qt
# longexit is et > -1.0 * sqrt_qt ... the opposite of long
self.lines.short = et > sqrt_qt
# shortexit is et < sqrt_qt ... the opposite of short
class St(bt.Strategy):
params = dict(
ksigs=False, # attempt trading
period=30,
)
def __init__(self):
if self.p.ksigs:
self.ksig = KalmanSignals()
KalmanFilter()
KalmanMovingAverage(period=self.p.period)
bt.ind.SMA(period=self.p.period)
if True:
kf = KalmanFilterInd()
kf.plotlines.sqrt_qt._plotskip = True
def next(self):
if not self.p.ksigs:
return
size = self.position.size
if not size:
if self.ksig.long:
self.buy()
elif self.ksig.short:
self.sell()
elif size > 0:
if not self.ksig.long:
self.close()
elif not self.ksig.short: # implicit size < 0
self.close()
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.YahooFinanceCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
data1 = bt.feeds.YahooFinanceCSVData(dataname=args.data1, **kwargs)
data1.plotmaster = data0
cerebro.adddata(data1)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Packages and Kalman'
)
)
parser.add_argument('--data0', default='../../datas/nvda-1999-2014.txt',
required=False, help='Data to read in')
parser.add_argument('--data1', default='../../datas/orcl-1995-2014.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='2006-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='2007-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='runonce=False',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()